Michael W. Sherman
Thank you for visiting my website.
I’m an artificial intelligence practitioner/applied researcher with expertise in machine learning systems and AI on text (NLP/NLU).
I currently work as a Machine Learning Engineer with Google Cloud Professional Services, where I build AI systems and provide AI strategy assistance to Google Cloud customers.
Work
Selected Professional Projects
Bloomberg Points of Law
I led machine learning and NLP work on a new Bloomberg product called Points of Law. I was the only member of the development team with prior machine learning experience.
Points of Law is a legal search product that mines 13 million court documents for key legal concepts and provides tools for lawyers to find the legal concepts most relevant to their cases. It was awarded the 2018 New Product Award by the American Association of Law Librarians.
Points of Law finds legal concepts in court documents and links to other court documents discussing the same legal concept:

Points of Law builds a timeline of every legal concept, tracing the evolution of the concept and revealing the court case where the concept was first used:
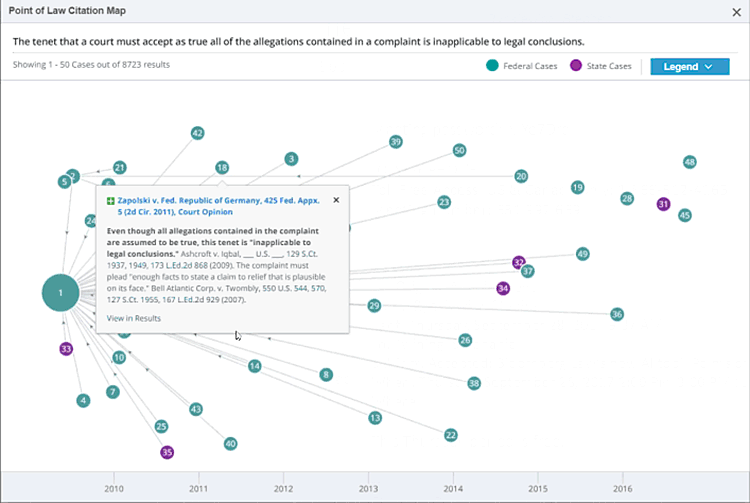
Far more lawyer time is spent researching past cases to find relevant points of law than in the actual courtroom. This product makes that research tens to hundreds of times faster.
Coverage:
- American Association of Law Librarians 2018 New Product Award.
- National Law Journal names Bloomberg Law a “Legal AI Leader” on the strength of Points of Law.
- ABA Journal (the American Bar Association) covers the release of Points of Law.
- Review from Law Librarian Blog.
Monitoring the U.S. Stock Market
As a Consultant at FIS (then Sungard), I was part of a bid team that architected and prototyped a system to build the Consolidated Audit Trail (CAT), a petabyte-scale data warehouse to track all activity in the American stock market–all orders, cancellations, trades, quotes, etc.
As part of our bid, we built a prototype that processed 6 billion transactions per hour and published a whitepaper discussing our scalability tests. In addition to driving the bidding process forward and designing the schema of the proposed data warehouse, I wrote the bulk of the whitepaper and ran the day-to-day engineering efforts of our Hadoop+Bigtable (Hbase) prototype.
We were awarded a U.S. patent for our Consolidated Audit Trail prototype.
Coverage:
- PCWorld interviews my team lead on the successful prototype.
- CNBC on the intense requirements of the Consolidated Audit Trail.
- Bloomberg on the whitepaper and prototype.
- Press Release from FIS.
Estimating the Cash Value of Financial Assets
I led a team of seven developers prototyping a machine learning system to predict daily cash values for $4T of financial assets held by customers at a large bank. Our system used the bank’s proprietary data in addition to publicly available data on the financial assets. We showed the client how they could use their data to more accurately estimate the cash value of financial assets versus using only publicly available data.
This project was the first use of Google Cloud for this customer. On the success of this project, the customer’s Google Cloud spend grew by 500% over the following six months and they agreed to become a public Google Cloud reference.
Improving Patent Search for the United States Patent and Trademark Office
Every year the U.S. Patent and Trademark Office (USPTO) processes over 250,000 patent applications. Each of these applications requires considerable manual attention from specialized patent examiners, who are responsible for ensuring the innovations in the patent application do not duplicate claims in the 10 million existing U.S. patents.
In collaboration with patent experts, I built machine learning models and a search pipeline to provide better search results to USPTO examiners. The search system did not resemble a conventional search engine, instead our approach was highly customized to the workflows of patent examiners. My specific contributions included the core machine learning model of one search tool, and a pipeline to filter hundreds of thousands of possible search results down to a small subset.
Coverage: FedScoop, GovCon Wire, Press Release.
Machine Learning Infrastructure with Kubernetes and Kubeflow
For a large manufacturing company, I designed an ML Platform. The company wanted to train models on the cloud then deploy those models on edge servers in manufacturing facilities and in traditional data centers. The platform design was based on Kubernetes+Kubeflow for better portability between these different serving contexts. To accommodate the security concerns of the manufacturer, the design had to carefully consider the necessity and appropriateness of each Kubeflow component.
Retail Pricing with Machine Learning
I architected an ML-based pricing system for a retail e-commerce platform with $3B+ of annual purchases. The architecture had many special considerations, including managing the different dollar amounts presented to the customer across a user session, processing requests from both the web and phone apps, and integrating a prediction service into a complex existing service-based system. I also planned the $1M professional services project to implement the proposed architecture.
Automated Data Entry
I was part of a team that built a series of machine learning models to automate new product data entry for a wholesaler with $100B+ of annual revenue. The data entry was for a highly regulated product category where data entry clerks had to gather multiple legally required pieces of paperwork, search the paperwork for key pieces of information, and enter the information into a database. We built a series of models that determined if the correct paperwork was available then extracted the key pieces of information from the paperwork.
Retail Demand Forecasting
I was the tech lead a team of two developers prototyping a demand forecasting system for a clothing retailer with $15B+ of annual sales. Our ML-based system outperformed the retailer’s existing forecasts by an amount worth “tens of millions of dollars” a year.
Energy Markets Dashboards
As a Consultant at FIS (then Sungard), I worked with the CEO of an energy investment fund to build dashboards monitoring the daily performance of the fund’s energy companies. Working with a team of energy analysts, I created a series of Tableau dashboards built on custom metrics. I also advised on changes to the underlying SQL data warehouse.
Better Workers’ Compensation Outcomes
I was part of a team of student consultants tasked by a large American retailer to mine their workers’ compensation data to discover medical treatment choices that led to faster recovery times.
We found a handful of decision points in the retailer’s workers’ compensation process where additional treatments sped up recovery. We also discovered new segments of claimants where identical treatments led to different outcomes.
Speaking
Speaking and Presentations
Practical Machine Learning for Financial Services
Keynote Speaker at UiPath Together NY, 2018
Productionization of Machine Learning
Panelist at Texas Analytics Summit 2018
Side Projects
Open Source Contributions
Gensim
Gensim is a popular python library for running NLP algorithms on large corpora. I added a method to automate training word2vec on multiple files, and added support for user-defined colocation detection metrics. Pull Requests.
Other Projects
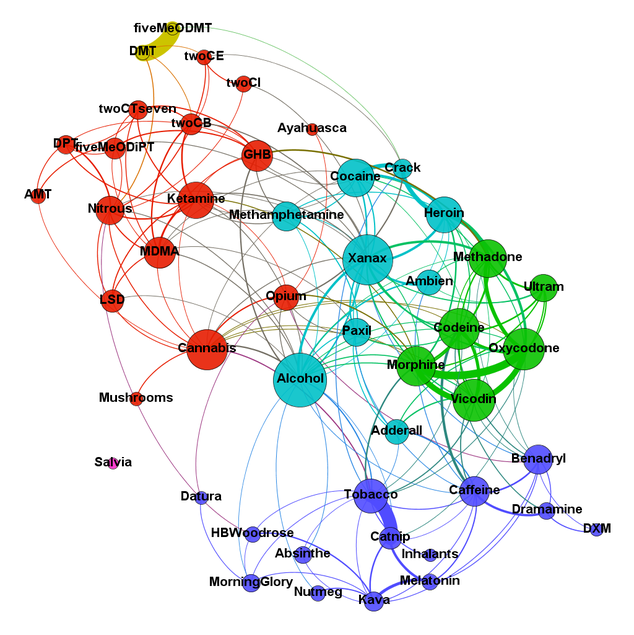
Erowid Web Forum Analysis
Erowid is a website that’s collected millions of first-hand accounts of drug abuse. I completed some text analytics. This was a graduate school project. Writeup.
Diabetes Prediction
Prediction of diabetes from other elements of a patient’s medical record. This was a graduate school project. Writeup.
Papers & More
Papers and Publications
Improving ML Training Data with Gold-Standard Quality Metrics
L. Barret and M. Sherman, “Improving ML Training Data with Gold-Standard Quality Metrics,” in KDD ‘19: 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Workshop on Data Collection, Curation, and Labeling (DCCL) for Mining and Learning, 5 August 2019, Anchorage, Alaska, USA [Online]. Available: https://research.google/pubs/pub48575/.
In this paper we propose techniques for managing a manual data labeling task when your labelers are experts. Most research on manual ML training data labeling assumes a crowdsourcing model where the annotators are commodities—expendable, replaceable, and quick to train. This is one of the few publications offering concrete recommendations on how to label data when your labelers are experts who cannot be replaced.
Civil Asset Forfeiture: A Judicial Perspective
L. Barret et al., “Civil Asset Forfeiture: A Judicial Perspective,” in Proceedings of the Data For Good Exchange 2017, 24 September 2017, New York, New York, USA [Online]. Available: https://arxiv.org/abs/1710.02041.
We data mined Bloomberg Law’s collection of court dockets to learn more about a law enforcement practice of seizing property without a guilty verdict.
Scaling to Build the Consolidated Audit Trail: A Financial Services Application of Google Cloud Bigtable
N. Palmer, M. Sherman, Y. Wang, and S. Just, “Scaling to Build the Consolidated Audit Trail: A Financial Services Application of Google Cloud Bigtable,” Google, 2015. [Online]. Available: https://cloud.google.com/bigtable/pdf/FISConsolidatedAuditTrail.pdf.
We tested write scalability of Google Cloud Bigtable on stock market transaction data.
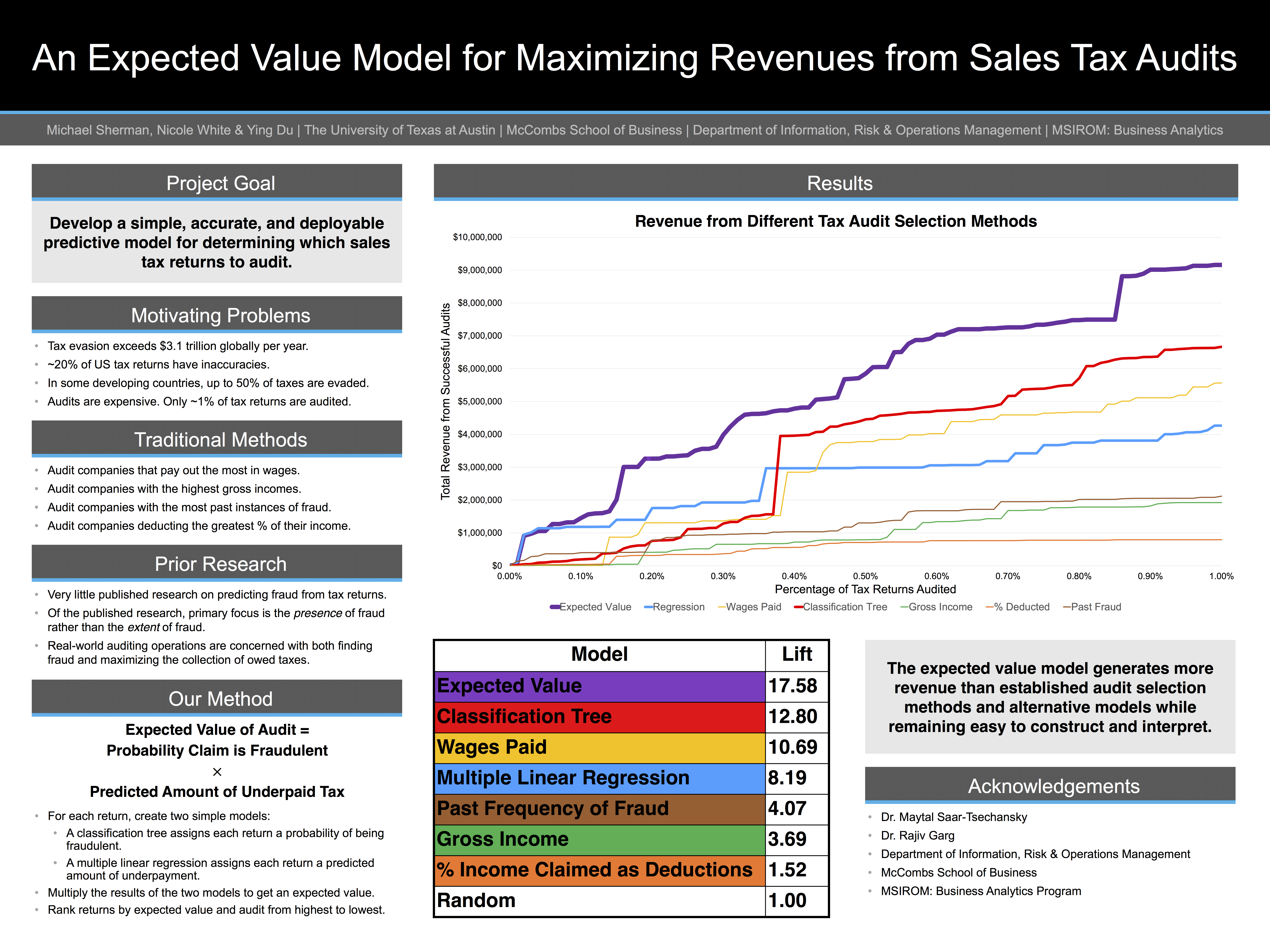
An Expected Value Model for Maximizing Revenues from Sales Tax Audits
M. Sherman, N. White, and Y. Du, “An Expected Value Model for Maximizing Revenues from Sales Tax Audits,” presented at Texas Workshop on Social and Business Analytics, 28 March 2014, Austin, Texas, USA [Online]. Available: https://www.michaelwsherman.com/web_img/audit_poster.png.
{kind=link}
We built a custom, interpretable model to maximize the revenue of tax audits. Poster.
Patents
N. Palmer and M. Sherman, “System and Associated Methodology of Creating Order Lifecycles via Daisy Chain Linkage,” U.S. Patent 10,089,687, 2 Oct., 2018.
Awards
2018 New Product of the Year by the American Association of Law Librarians for Bloomberg Points of Law
I led machine learning and NLP, and was the only development team member with machine learning experience.
2016 Bloomberg Verticals TechFest Winner (Internal Award)
Awarded for “applying deep learning to NLP tasks.” My team trained the first deep learning models in our working group.
2015 Sungard Consulting STAR Award (Internal Award)
Awarded for “exceeding expectations in sales, leadership, or deliverables,” awarded to 4 consultants annually (of about 200). I led the day-to-day work on a prototype system to process 6 billion stock market transactions per hour and wrote the bulk of the companion whitepaper.